
OWASP Benchmark: How Useful Is It for SAST?

Strong and not-so strong sides of using it for your SAST benchmarks…
There’s no escape. When you are choosing a Static Application Security Testing (SAST) tool, a comparison is a must for measuring speed, accuracy, usability… There are many sides to this comparison and a sample application is usually used as a play ground, such as the OWASP Benchmark project. But is it enough to figure out or even compare the most important qualities of a SAST tool?
OWASP Benchmark
Straight from the source code repository, here’s the goal of the project.
The OWASP Benchmark Project is a Java test suite designed to verify the speed and accuracy of vulnerability detection tools.
The software is a basic Java Servlet application containing ~2700 individual test cases each represented with a pair of a source code (.java) and a description file (.xml).
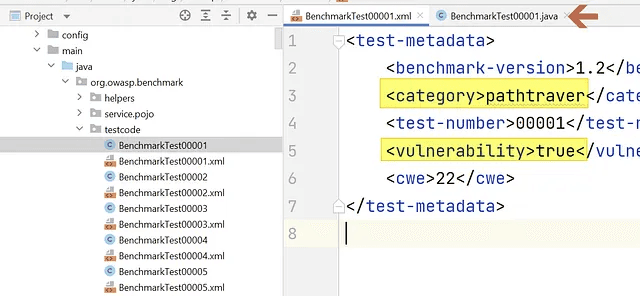
The XML file contains the name of the vulnerability implemented in the Java file in <category> element and it also contains whether the it’s implemented as a false positive (FP) or not in<vulnerability>element. Apparently, the latter is a way to measure the accuracy of a SAST or a DAST tool, which we will focus on the first one.
There are a lot of test cases trying to find clever ways to goof around with the accuracy of the solutions compared, however, there are only 11 unique weaknesses that the vulnerabilities belong to;
Path Traversal
Insecure Hash Algorithm
Trust Boundary Violation, CWE 501
Insecure Encryption Algorithm
Command Injection
SQL Injection
Insecure Random Number Generation
LDAP Injection
Cross Site Scripting
Missing Cookie Secure Attribute, CWE 614
XPath Injection
Pretty forward, well-known weaknesses to benchmark a SAST solution. Most of them are injection type weaknesses which can also permit to compare data flow analysis engines.
A Simple Analysis
If we leave the basic weakness analysis engine processes to locate a vulnerability aside, the main goal behind the project is measuring the accuracy.
In that terms, the project does what it advertises. There are conditions placed in the test code which will so to speak try to fool the tools that are run against it and force them to produce false positives (FPs).
Let’s analyze a few of these techniques used in the OWASP Benchmark project here;
Dead code
In the code block below, assume the param comes from a dangerous source. It turns out that the else statement contains a dead code. With that line never runs, there shouldn’t be any vulnerability as the tainted data never arrives at DangerousMethod.
Complex Data Structures
A similar pattern that we can find to mess with the SAST tools is using the data structures such as ArrayLists. In the code block below, assume that the param comes from a dangerous source.
If you carefully trace the code, it turns out that the bar is always a safe value. It will never carry the potentially dangerous value of param to the DangerousMethod.
Simple Inter-Procedural Calls
Here’s another example. ProcessBuilder is a dangerous sink that the data arrives to it should be traced. On the code block below, the args contains a param which comes from an external class method call that returns a hardcoded value.
Here’s the getTheValue method that returns a safe value, albeit, the class itself is constructed with HttpServletRequest mischievously.
Configurational Values
The source code reads a property value with a strong cryptographic algorithm as a default value when the key is missing in the properties file.
But the actual value exists in the properties file as a weak cryptographic algorithm;
A Short Critique
Although it contains a web based interface, the application itself is not designed to include code flows or design complexity that even a normal web application usually has, such as services, repositories, etc.
There are well-known techniques that SAST tools are using to analyze the code statically and find out issues. Some of these techniques also produce false positives and that’s inevitable since the resources, such as CPU and memory, are limited.
The goal of every SAST tool is to reduce the number of FPs it produces. So, in order to benchmark a SAST tool about the accuracy related techniques they use it might be a better idea to write test cases targeting the techniques available :).
FlowBlot.NET is such a tool limited to evaluation of flow based techniques. You can read more about these here and here. The first blog post writes about different sensitivities in static analysis and the latter article introduces and explains the FlowBlot.NET somewhat in detail.
Sure, some of the coding techniques to fool the SAST tools in the OWASP Benchmark project overlaps with some of the test cases in FlowBlot.NET, but not too much.
Here are the grouped test cases in FlowBlot.NET;
On Missing Cookie Secure Attribute (securecookie) Case
This category is a curious one we spotted in OWASP Benchmark project while analyzing it. At first, it seems securecookie test case is focusing on HTTP Response Splitting weakness reference with CWE 113 code, which leads to lots of other vulnerabilities, such as XSS, Cache Poisoning, Open Redirects, etc.
However, as with the CWE 614 the paired XML file references in the project itself, in reality this test case focuses on the existence of Secure attributes on HTTP Cookies.
There are 67 test cases related to this weakness and although the code really tries hard to fool SAST tools, the identification of a TP/FP is quite easy for a semantic analyzer.
Because no matter how complex the data flow is, it all boils down to this piece of code shown in bold;
When the setSecure is called with false, any issued vulnerability is a True Positive. And when it is called with a boolean value of true, it’s a False Positive.
Conclusion
Comparing SAST tools is a hard task. There are good deliberately vulnerable source code projects out there, such as OWASP Benchmark, OWASP Web.Goat, FlowBlot.NET, however, they are not enough to decide every criteria under the analysis.
It’s better to know one or two things about the internal workings of a SAST tool, such as the techniques it’s using, in order to give educated decisions when choosing. Even for a small task of choosing the correct benchmark test bed.
Blogs
Read Our Blogs and News
Discover expert insights, trends, and tips that help you navigate the world of finance and technology.



