
Introducing Agent Component Security Index
Introducing Agent Component Security Index
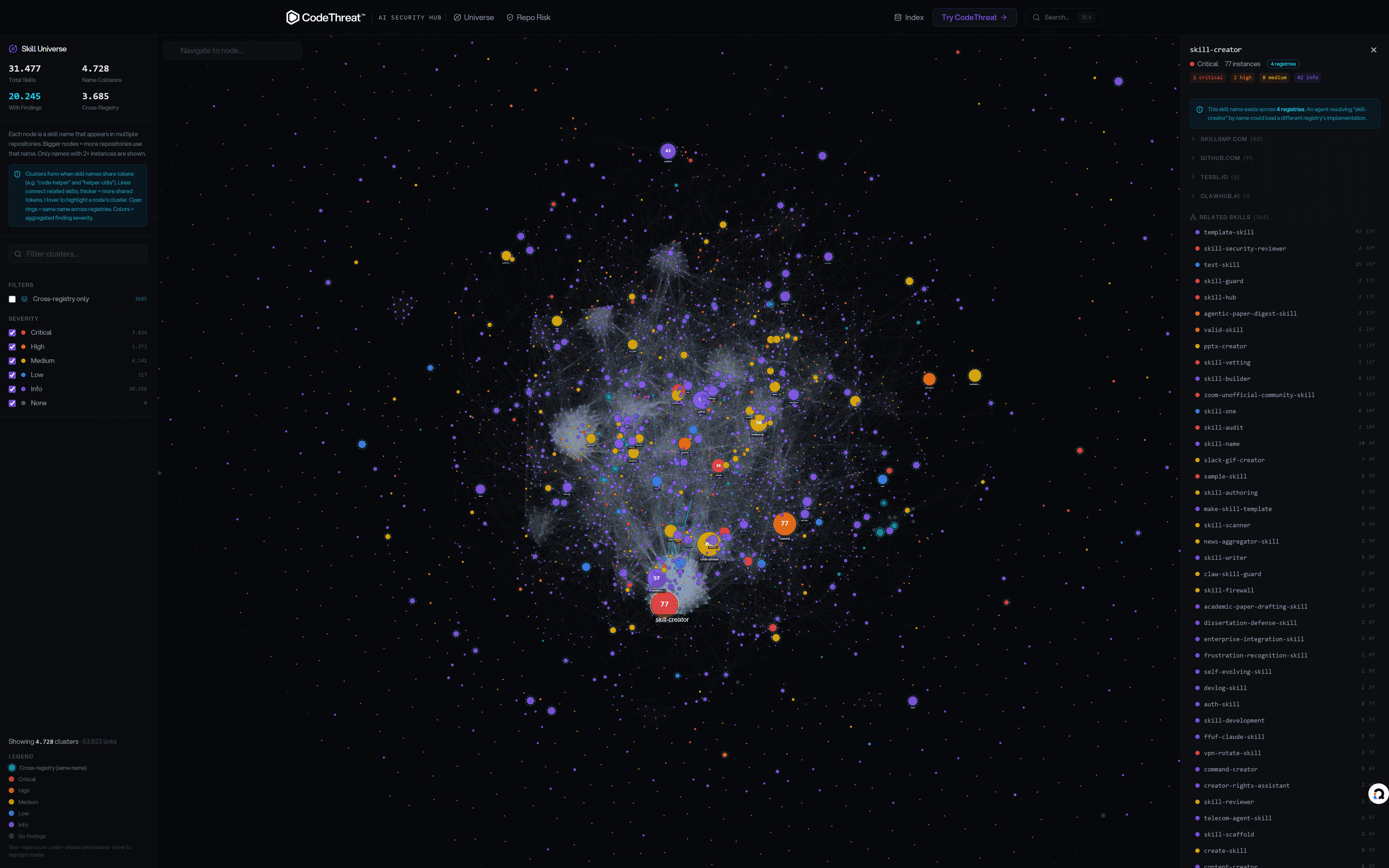
The Agent Component Security Index indexes skills and MCP servers from SkillsMP, GitHub, ClawHub, Tessl, the MCP registry, npm, and other registries. For each artifact we capture metadata, tool definitions, SKILL.md content, and scan results.
We read the code, instructions, and manifests to find risky patterns: prompts that could be manipulated, hidden capabilities, or code that could exfiltrate data. Where we can run the artifact safely, we also observe what it actually does at runtime (file access, API calls, shell commands) to catch behavior that only shows up when executed.
Each artifact gets a risk profile: severity breakdown, capability summary, and a score. You see what tools it can call, what files it can read, and whether it has known patterns for prompt injection, data exfiltration, or unauthorized tool use.
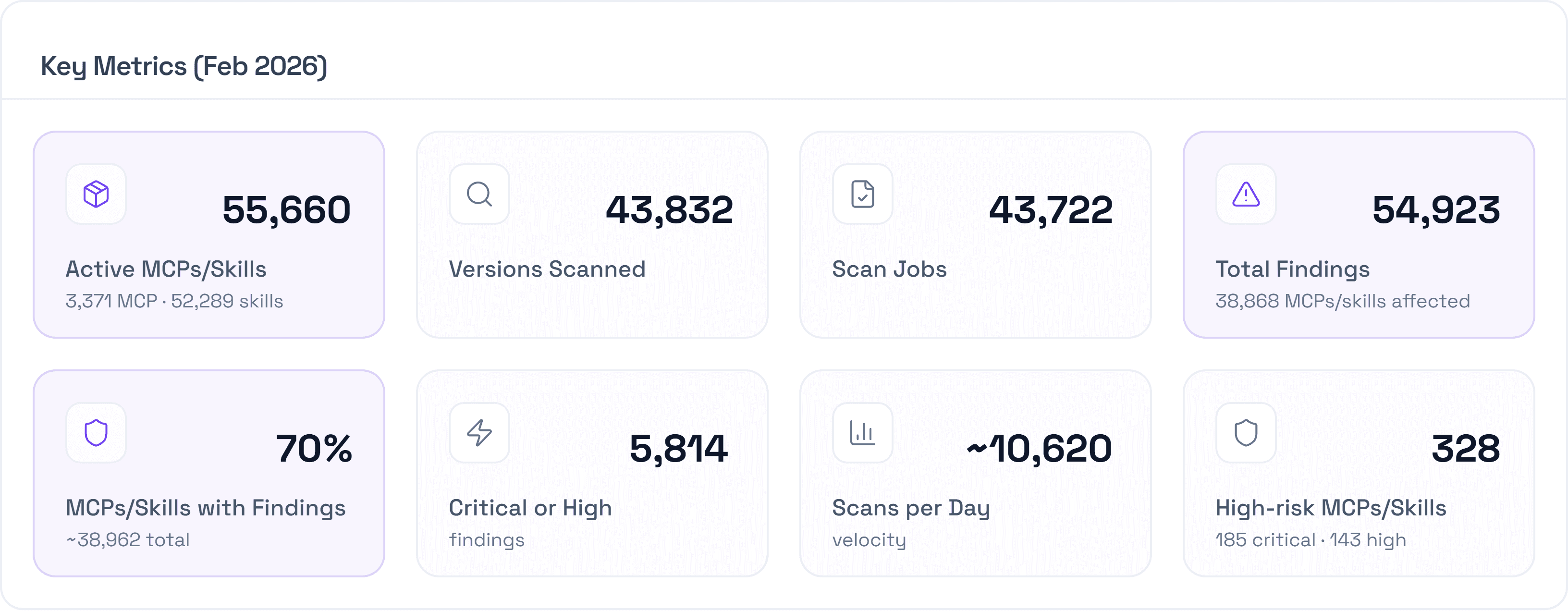
Here is a breakdown of what we did this month.
Why It Exists
Developers adopt skills and MCP servers without knowing what they can do. The index closes that gap. Think OSS Index or Socket.dev, but for agentic AI. Open, standardized, actionable.
The agentic supply chain is growing faster than visibility. New skills and MCP servers ship daily. Without a central index, teams either adopt blindly or spend hours manually auditing. The index gives you a single place to check before you integrate.
Intentional vs. Risky
Not every finding is a vulnerability. A skill that needs network access or an MCP server that runs shell commands by design will still surface. We show it anyway. These components read files, call APIs, change systems. Capabilities stay visible so you decide what fits your risk tolerance.
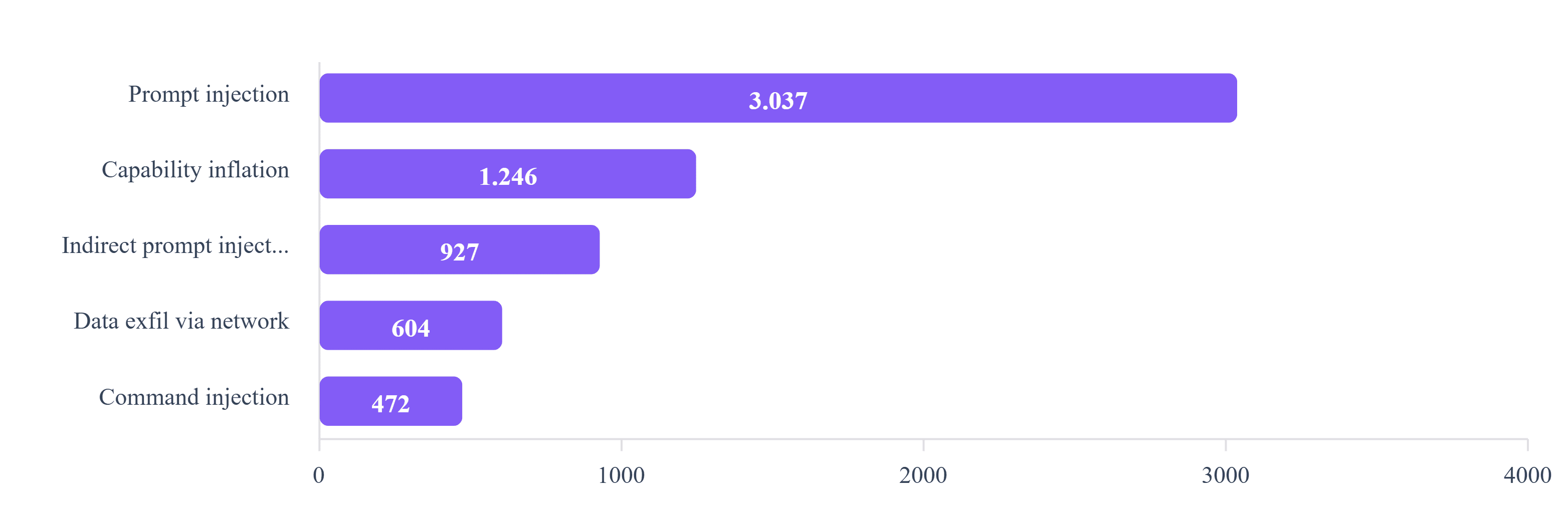
Policy findings (missing license, invalid naming) are common and often low risk. Security findings (prompt injection, data exfiltration, command injection) need closer review. We surface both. You decide what matters for your environment.
Most common security finding types
How It Works

What We Look For
For policy
missing license
invalid naming
incomplete manifest
For security
instructions that could be manipulated to make the agent do something unintended
instructions that process user content without sanitizing it
skills that claim to do less than they actually can
code or instructions that could send data outside your environment
skills that can discover and use other skills without consent
access to shell, network, or file system that the skill claims it does not need
When to Use It
Before adopting a skill or MCP server: search the index, open the artifact profile, and review findings. If the risk score is high or critical findings appear, dig into the details before you integrate.
During procurement or vendor evaluation: use the index to compare artifacts. Some registries have more policy-compliant artifacts; others have higher rates of security findings. The numbers help you set expectations.
If the artifact is not yet indexed: submit it via skillaudit.sh. We scan and add it. You get a profile; the index grows. The more artifacts we index, the more useful the index becomes for everyone.
Blogs
Read Our Blogs and News
Discover expert insights, trends, and tips that help you navigate the world of finance and technology.



